score function:maps the raw data to class scores
loss function:quantifies the agreement between the predicted scores and the ground truth labels.
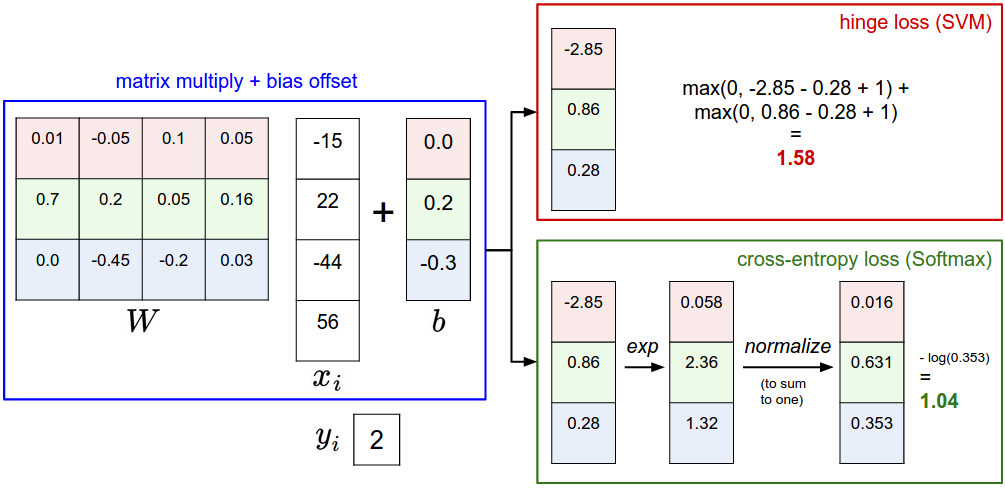
2.Linear classification(Score Function)
f(xi,W,b)=Wxi+b
SVM : support vector machine(Loss Function)
Li=∑j≠yimax(0,wTjxi−wTyixi+Δ)
threshold at zero max(0,−) function is often called the hinge loss.
Regularization. (用來達成簡單的函數模型而不至於overfitting training data)
R(W)=∑k∑lW2k,l
That is, the full Multiclass SVM loss becomes
L=1N∑iLidata loss+λR(W)regularization loss
or
L=1N∑i∑j≠yi[max(0,f(xi;W)j−f(xi;W)yi+Δ)]+λ∑k∑lW2k,l
Binary Support Vector Machine
Li=Cmax(0,1−yiwTxi)+R(W)
Multiclass Support Vector Machine loss
Li=∑j≠yimax(0,wTjxi−wTyixi+Δ)Softmax classifier:(Loss Function)
Li=−log(efyi∑jefj)or equivalentlyLi=−fyi+log∑jefj
H(p,q)=−∑xp(x)logq(x)
沒有留言:
張貼留言